
Model baru ini, yang disebut VSSFlow, memanfaatkan arsitektur kreatif untuk menghasilkan suara dan ucapan dengan satu sistem terpadu, dengan hasil yang canggih. Tonton (dan dengarkan) beberapa demo di bawah.
Masalahnya
Saat ini, sebagian besar model video-ke-suara (yaitu model yang dilatih untuk menghasilkan suara dari video senyap) tidak terlalu bagus dalam menghasilkan ucapan. Demikian pula, sebagian besar model text-to-speech gagal menghasilkan suara non-ucapan, karena model tersebut dirancang untuk tujuan yang berbeda.
Selain itu, upaya sebelumnya untuk menyatukan kedua tugas sering kali didasarkan pada asumsi bahwa pelatihan bersama menurunkan kinerja, sehingga mengarah pada pengaturan yang mengajarkan ucapan dan suara dalam tahapan terpisah, sehingga menambah kompleksitas pada alur kerja.
Berdasarkan skenario ini, tiga peneliti Apple, bersama enam peneliti dari Universitas Renmin Tiongkok, mengembangkannya VSSFlowmodel AI baru yang dapat menghasilkan efek suara dan ucapan dari video senyap dalam satu sistem.
Tidak hanya itu, arsitektur yang mereka kembangkan bekerja sedemikian rupa sehingga pelatihan bicara meningkatkan pelatihan suara, dan sebaliknya, daripada mengganggu satu sama lain.
Solusinya
Singkatnya, VSSFlow memanfaatkan berbagai konsep AI generatif, termasuk mengubah transkrip menjadi rangkaian fonem token, dan belajar merekonstruksi suara dari derau dengan pencocokan aliran, yang pada dasarnya melatih model agar secara efisien memulai dari derau acak dan berakhir dengan sinyal yang diinginkan.
Semua itu tertanam dalam arsitektur 10 lapisan yang memadukan sinyal video dan transkrip langsung ke dalam proses pembuatan audio, sehingga model dapat menangani efek suara dan ucapan dalam satu sistem.
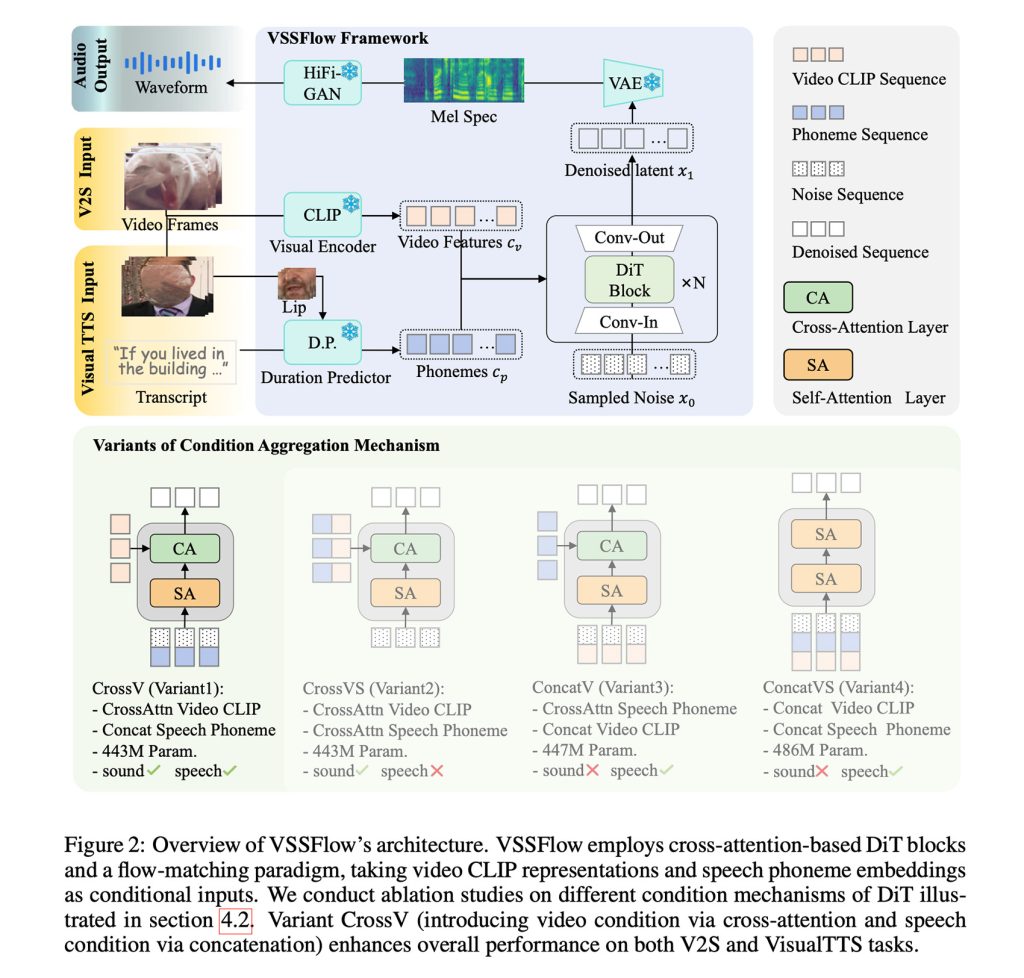
Mungkin yang lebih menarik, para peneliti mencatat bahwa sebenarnya pelatihan bicara dan suara digabungkan peningkatan kinerja pada kedua tugasdaripada menyebabkan keduanya bersaing atau menurunkan kinerja keseluruhan tugas.
Untuk melatih VSSFlow, para peneliti memberikan model tersebut campuran video senyap yang dipasangkan dengan suara lingkungan (V2S), video percakapan senyap yang dipasangkan dengan transkrip (VisualTTS), dan data text-to-speech (TTS), sehingga memungkinkan model mempelajari efek suara dan dialog lisan secara bersamaan dalam satu proses pelatihan menyeluruh.
Yang penting, mereka mencatat bahwa VSSFlow tidak dapat secara otomatis menghasilkan suara latar belakang dan dialog lisan secara bersamaan dalam satu keluaran.
Untuk mencapai hal tersebut, mereka menyempurnakan model yang sudah dilatih pada sejumlah besar contoh sintetik yang menggabungkan suara ucapan dan suara lingkungan, sehingga model tersebut akan mempelajari seperti apa seharusnya suara keduanya secara bersamaan.
Menerapkan VSSFlow untuk bekerja
Untuk menghasilkan suara dan ucapan dari video senyap, model ini memulai dari kebisingan acak dan menggunakan isyarat visual yang diambil sampelnya dari video dengan kecepatan 10 frame per detik untuk membentuk suara sekitar. Pada saat yang sama, transkrip dari apa yang dikatakan memberikan panduan yang tepat untuk suara yang dihasilkan.
Saat diuji terhadap model khusus tugas yang dibuat hanya untuk efek suara atau ucapan saja, VSSFlow memberikan hasil yang kompetitif di kedua tugas tersebut, unggul dalam beberapa metrik utama meskipun menggunakan satu sistem terpadu.
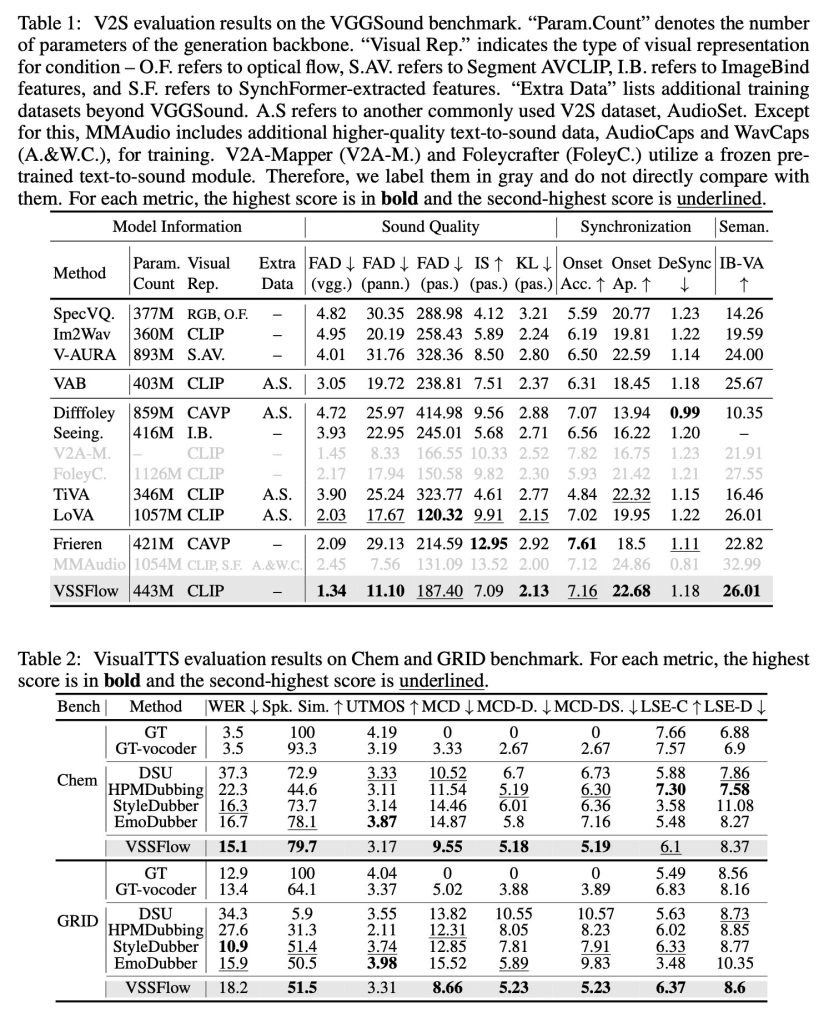
Para peneliti menerbitkan beberapa demo hasil suara, ucapan, dan pembuatan gabungan (dari video Veo3), serta perbandingan antara VSSFlow dan beberapa model alternatif. Anda dapat melihat beberapa hasilnya di bawah, tetapi pastikan untuk mengunjunginya halaman demo untuk melihat semuanya.
Dan inilah sesuatu yang sangat keren: para peneliti kode VSSFlow sumber terbuka di GitHubdan sedang berupaya untuk membuka bobot model juga. Selain itu, mereka berupaya menyediakan demo inferensi.
Mengenai apa yang mungkin terjadi selanjutnya, para peneliti mengatakan:
Karya ini menyajikan model aliran terpadu yang mengintegrasikan tugas video-to-sound (V2S) dan visual text-to-speech (VisualTTS), membangun paradigma baru untuk pembuatan suara dan ucapan yang dikondisikan video. Kerangka kerja kami menunjukkan mekanisme agregasi kondisi yang efektif untuk menggabungkan kondisi ucapan dan video ke dalam arsitektur DiT. Selain itu, kami mengungkapkan efek saling meningkatkan pembelajaran gabungan suara-ucapan melalui analisis, menyoroti nilai model generasi terpadu. Untuk penelitian masa depan, ada beberapa arah yang perlu dieksplorasi lebih lanjut. Pertama, kelangkaan data suara-video berkualitas tinggi membatasi pengembangan model generatif terpadu. Selain itu, mengembangkan metode representasi suara dan ucapan yang lebih baik, yang dapat mempertahankan detail ucapan sekaligus mempertahankan dimensi yang ringkas, merupakan tantangan penting di masa depan.
Untuk mempelajari lebih lanjut tentang penelitian yang berjudul “VSSFlow: Menyatukan Generasi Suara dan Ucapan yang Dikondisikan Video melalui Pembelajaran Bersama,” ikuti tautan ini.
Penawaran aksesori di Amazon
![]()
![]()
FTC: Kami menggunakan tautan afiliasi otomatis yang menghasilkan pendapatan. Lagi.













{kind=link}