
Sekelompok peneliti Apple dan Universitas Tel-Aviv menemukan cara untuk mempercepat pembuatan text-to-speech berbasis AI tanpa mengorbankan kejelasan. Begini cara mereka melakukannya.
Pendekatan baru yang menarik untuk menghasilkan ucapan lebih cepat
Dalam makalah baru berjudul Penerimaan Berbutir Kasar yang Berprinsip untuk Penguraian Kode Spekulatif dalam Pidato Peneliti Apple merinci pendekatan menarik untuk menghasilkan ucapan dari teks.
Meskipun saat ini ada beberapa pendekatan untuk menghasilkan ucapan dari teks, para peneliti berfokus pada model text-to-speech autoregresif, yang menghasilkan token ucapan satu per satu.
Jika Anda pernah melihat cara kerja sebagian besar version bahasa besar, Anda mungkin akrab dengan design autoregresif, yang memprediksi token berikutnya berdasarkan semua token yang ada sebelumnya.
Pembuatan ucapan autoregresif bekerja dengan cara yang umumnya serupa, hanya saja tokennya mewakili potongan sound, bukan kata atau karakter.
Meskipun ini adalah cara yang efisien untuk menghasilkan ucapan dari teks, pendekatan ini juga menciptakan hambatan pemrosesan, seperti yang dijelaskan oleh peneliti Apple:
Namun, untuk LLM ucapan yang menghasilkan token akustik, pencocokan token yang tepat terlalu membatasi: banyak token diskrit yang dapat dipertukarkan secara akustik atau semantik, sehingga mengurangi tingkat penerimaan dan membatasi percepatan.
Dengan kata lain, model ucapan autoregresif bisa jadi terlalu ketat, sering kali menolak prediksi yang cukup baik, hanya karena design tersebut tidak cocok dengan token yang diharapkan oleh design. Hal ini, pada gilirannya, memperlambat segalanya.
Masuk, Prinsip Butir Kasar (PCG)
Singkatnya, solusi Apple didasarkan pada premis bahwa banyak token berbeda dapat menghasilkan suara yang hampir sama.
Oleh karena itu, Apple mengelompokkan token ucapan yang terdengar serupa, sehingga menciptakan langkah verifikasi yang lebih fleksibel.
Dengan kata lain, alih-alih memperlakukan setiap kemungkinan suara sebagai sesuatu yang benar-benar berbeda, pendekatan Apple memungkinkan model menerima token yang termasuk dalam kelompok “kesamaan akustik” umum yang sama.
Faktanya, PCG terdiri dari dua design: design yang lebih kecil yang dengan cepat mengusulkan token ucapan, dan version juri kedua yang lebih besar yang memeriksa apakah token tersebut termasuk dalam kelompok akustik yang tepat sebelum menerimanya.
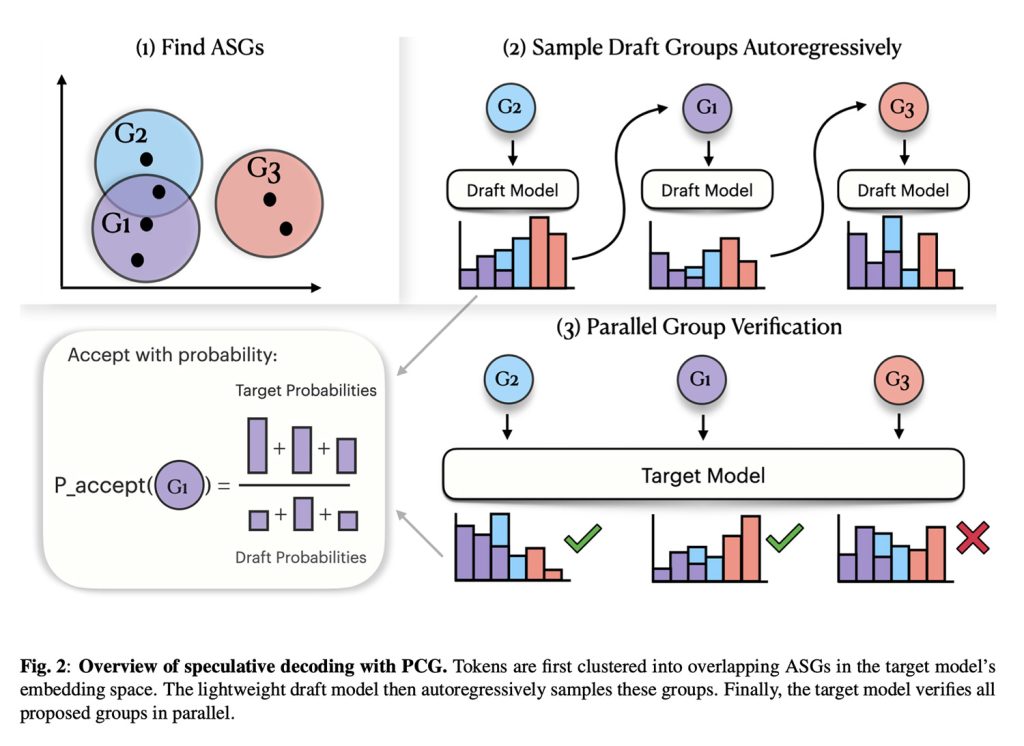
Hasilnya adalah kerangka kerja yang mengadaptasi konsep translating spekulatif (SD) ke LLM yang menghasilkan token akustik, yang pada gilirannya mempercepat pembuatan ucapan sekaligus memastikan kejelasan.
Dan dari segi hasil, para peneliti menunjukkan bahwa PCG meningkatkan produksi ucapan sekitar 40 %, sebuah peningkatan yang signifikan, mengingat penerapan decoding spekulatif standar pada design ucapan hampir tidak meningkatkan kecepatan sama sekali.
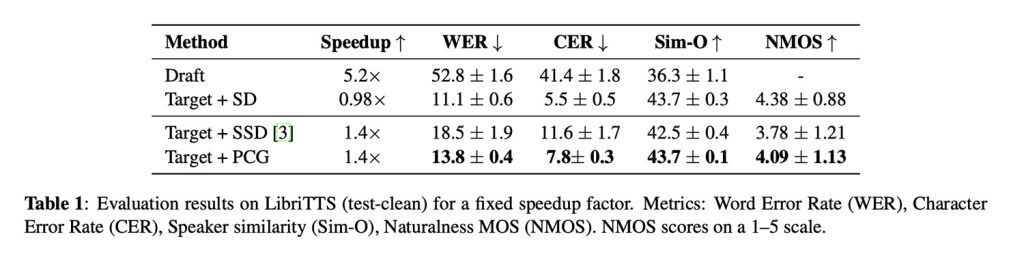
Pada saat yang sama, PCG menjaga tingkat kesalahan kata pada tingkat yang lebih rendah dibandingkan metode yang berfokus pada kecepatan sebelumnya, mempertahankan kesamaan pembicara, dan mengungguli pendekatan yang berfokus pada kecepatan sebelumnya, dengan mencapai skor kealamian 4, 09 (standar penilaian manusia sebesar 1– 5 tentang seberapa alami ucapan tersebut terdengar).
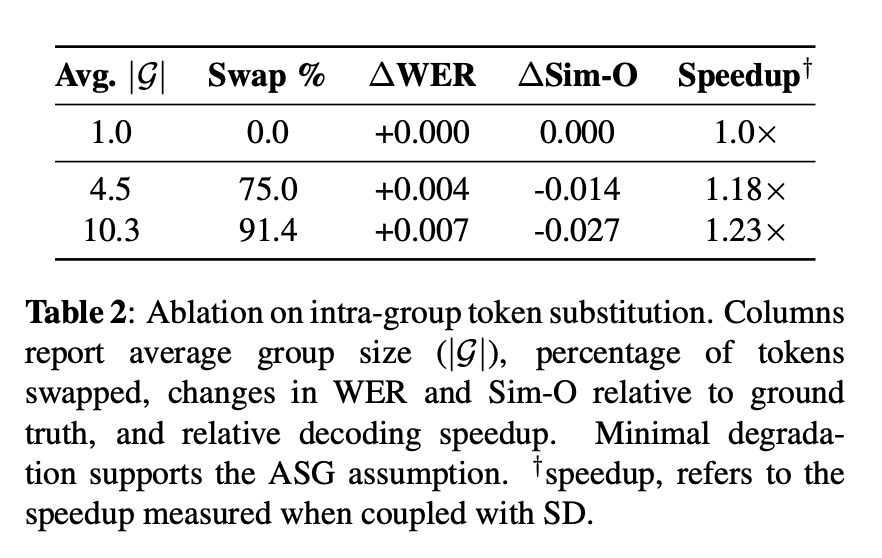
Dalam satu cardiovascular test (Ablasi pada substitusi token intra-grup), para peneliti mengganti 91, 4 % token ucapan dengan alternatif dari grup akustik yang sama, dan sound tetap bertahan, dengan hanya peningkatan sebesar +0, 007 pada tingkat kesalahan kata dan penurunan sebesar − 0, 027 pada kesamaan pembicara:
Apa arti PCG dalam praktiknya
Meskipun penelitian ini tidak membahas dampak temuannya dalam praktik bagi produk dan system Apple, pendekatan ini mungkin relevan untuk fitur suara masa depan yang perlu menyeimbangkan kecepatan, kualitas, dan efisiensi.
Yang penting, pendekatan ini tidak memerlukan pelatihan version target, karena ini merupakan perubahan waktu decoding. Dengan kata lain, ini adalah penyesuaian yang dapat diterapkan pada design ucapan yang ada pada waktu inferensi, daripada memerlukan pelatihan ulang atau perubahan arsitektural.
Terlebih lagi, PCG memerlukan sumber daya tambahan yang minimal (hanya sekitar 37 MB memori untuk menyimpan grup kesamaan akustik), sehingga praktis untuk diterapkan pada perangkat dengan memori terbatas.
Untuk mengetahui lebih lanjut tentang PCG, termasuk rincian teknis mendalam tentang kumpulan data dan konteks tambahan mengenai metode evaluasi, ikuti tautan ini
Penawaran aksesori di Amazon
FTC: Kami menggunakan tautan afiliasi otomatis yang menghasilkan pendapatan. Lagi.













{kind=link}